Présentation
préliminaire du schéma VITAM conçu pour le versement d’archives - 3/3
Exemples d'utilisation
Dans le cadre du programme VITAM, nous devons
définir les interfaces externes de la solution logicielle que nous
allons développer. Parmi ces interfaces, le schéma de données
accompagnant un versement d’archives est un enjeu important.
Ce troisième billet porte sur des exemples
d’utilisation de ce schéma, exemples orientés mis en œuvre et
non métier (au sens où nous ne décrirons pas les métadonnées de
description mais uniquement les modalités de construction d’un
fichier XML).
Toujours à titre personnel, ceci ne constitue
pas une publication officielle mais un moyen de recueillir des avis
avant la mouture finale, toujours avec appel à commentaires.
Pour rappel, nous nous plaçons dans le cadre des
normes et règlements français, nous nous inspirons de la norme
MEDONA de l’AFNOR (Z
44-022) qui permet de définir le sur-ensemble des échanges
entre partenaires autour d’un Système d’Archivage Électronique
(SAE). Nous nous inspirons également de MoReq2010
pour le modèle de données.
Comme pour le précédent billet, vous êtes bien
sûr, vous lecteurs, plus que les bienvenus à apporter vos
commentaires.
Différentes implémentations selon les volumes
Ce chapitre présente
différentes modalités d’usage du schéma XML. Ces types sont bien
sûr mixables.
Modèle d’usage « tout en un »
Il s’agit d’avoir un seul fichier XML contenant
l’ensemble des 4 types de métadonnées (transport, technique,
gestion et descriptif). Cette approche est limitée aux cas où la
dimension du fichier XML final reste acceptable (quelques
mégaoctets).
| Illustration 1: ArchiveTransfer |
Toutes les données se retrouvent donc dans un seul
fichier XML, limitant ainsi son usage aux cas où la taille du
fichier reste exploitable par des environnements informatiques de
production. Il faut en effet anticiper les capacités de traitement
informatiques qui sont limitées par nature par les capacités
mémoire notamment des ordinateurs.
Modèle d’usage « par type »
L’objet de ce cas d’usage est d’avoir un
fichier XML par type de métadonnées, à savoir un premier fichier
contenant ArchiveTransfer
et le bloc de métadonnées de transfert, puis 2 fichiers XML
référencés par celui-ci, un pour les métadonnées de description
et de gestion (DescriptiveFilePackage
depuis DescriptiveMetadataPackage)
et un pour les métadonnées techniques (TechnicalFilePackage
depuis TechnicalMetadataPackage).
Il s’agit donc ici d’avoir 3 fichiers XML, sans
doute produit par 3 outils différents :
- Le fichier XML pour les métadonnées de transport utilisant un outil de création d’enveloppe de versements d’archives ;
- Le fichier XML pour les métadonnées descriptives et de gestion utilisant des outils liés aux métiers concernés (accès aux bases de données, au plan de classement d’origine, …) ;
- Le fichier XML pour les métadonnées techniques utilisant des outils d’identification technique.
 |
Illustration 2: Schéma VITAM - découpage par type |
| Illustration 3: DataObjectPackage |
| Illustration 4: DescriptiveMetadataPackage |
| Illustration 5: TechnicalMetadataPackage |
Modèle d’usage « par classement »
L’objet de ce modèle d’usage est de découper
le fichier XML contenant les métadonnées de description et de
gestion en autant de fichiers que de plans de classement différents
présents dans le même versement. L’intérêt de cette approche
est de permettre par exemple l’intégration de multiples versements
issus de métiers différents dans un seul et même container de
transfert.
L’illustration du schéma VITAM ci-dessous indique
le découpage en fichiers XML par racine de plan de classement
LevelDescriptiveMetadata
(1 dans Illustration 6: Schéma VITAM - Fichier par Classement).
 |
| Illustration 6: Schéma VITAM - Fichier par Classement |
L’entrée (2) LevelDescriptiveMetadataFile
positionnée sous l’entrée (1) du LevelDescriptiveMetadata
(cf Illustration 7: Éclatement par plan de classement) permet de
préciser un fichier XML pour chacune des racines des plans de
classement, c’est-à-dire au niveau le plus haut de
DescriptiveMetadata.
L’objet LevelDescriptiveMetadataFile
est une référence à un fichier externe, comme pour tous les
fichiers référencés dans le schéma VITAM. Sa déclaration est
dans la liste des fichiers binaires transmis (bloc DataObjectPackage
/ BinaryDataObject).
| Illustration 7: Éclatement par plan de classement |
Modèle d’usage « par fichier »
Le modèle par fichier
implique de créer un fichier XML par objet d’archives transmis.
Ces sous fichiers peuvent aussi bien concerner le détail des
métadonnées techniques que le détail des métadonnées
descriptives et de gestion (voir le premier billet).
Dans le schéma
ci-dessous est illustré ce modèle d’usage par fichier d’un
découpage en multiples fichiers XML.
 |
| Illustration 8: Schéma VITAM - par fichier |
Cette approche est
notamment pertinente lorsque les outils qui génèrent ces
métadonnées, créent le contenu XML par fichier dans des fichiers
XML indépendant. Par exemple, l’outil d’extraction des
métadonnées techniques pourrait identifier un seul fichier à la
fois, et donc générer un fichier XML par fichier analysé,
conduisant à ce formalisme « par fichier ».
Cas d’usage
Dans ce chapitre, nous présentons quelques exemples
d’usage du schéma VITAM pour répondre à des besoins
particuliers.
Versement d’un plan de classement
Il
s’agit de pouvoir faire le versement d’un plan de classement sans
archives, c’est-à-dire le versement uniquement de l’arbre de
métadonnées symbolisant le plan de classement, en tant que phase
préparatoire, sans les parties liées aux archives qui seront
versées dans un temps ultérieur.
Cela
permet par exemple de limiter plus tard les métadonnées lors des
versements des archives aux seules métadonnées liées à ces
archives, et non au plan de classement immuable associé.
Un
exemple métier type pourrait être le cas du recrutement d’un
nouvel agent, impliquant la création d’un « dossier agent »
avec l’ensemble des sous-dossiers susceptibles d’accueillir les
pièces de son dossier (recrutement, notation, avancement, congés,
formation et développement des compétences, cessation de fonctions,
…).
Pour
ce faire, il suffit de ne positionner aucun DataObject
ni TechnicalMetadata :
- Dans le bloc DataObjectPackage :
- 0 BinaryDataObject,
- 0 PhysicalDataObject,
- 0 TechnicalMetadataPackage.
- Dans le bloc DescriptiveMetadata :
- des LevelDescriptiveMetadata se terminant par des NullObject (cerclés de vert) une fois atteinte la profondeur désirée dans le plan de classement versé ;
- l’objet NullObject permet de mettre fin à la récursivité de manière contrôlable dans un schéma XML et ainsi d’indiquer qu’il n’y a pas d’objets d’archives associés à ce plan de classement.
Le
schéma ci-dessous illustre le format du fichier XML versé. Il est
vraisemblable que le versement ne sera alors constitué que d’un
seul fichier XML.
 |
| Illustration 9: Schéma VITAM - plan de classement |
Versement d’un ensemble de fichiers en tant que multiples version d’un seul objet d’archive
Il
s’agit de pouvoir verser un objet d’archives intellectuellement
unique mais sous de multiples représentations (version de
conservation, version de diffusion, version vignette, …). Cet objet
intellectuel d’archives unique sera décrit (bloc descriptif et
gestion) une seule fois, tandis que chaque représentation
(conservation, diffusion, vignette, ...) sera décrite techniquement
indépendamment (format du fichier, empreinte, …) puisqu’il
s’agit à chaque fois d’un fichier numérique différent.
On
peut également utiliser cette technique pour verser une version
papier d’un objet d’archives (l’original papier) et une version
scannée de ce même objet (version de diffusion). Les deux objets
seront alors deux représentations du même document intellectuel.
Pour
ce faire, dans la partie technique, illustrée dans le schéma
ci-dessous :
- L’objet intellectuel d’archives unique est identifié par le DataObjectGroupReferenceId en (2) ;
- Chaque représentation de cet objet intellectuel sera identifié par le BinaryDataObjectReferenceId en (1) et sa version (sa nature : conservation, diffusion, vignette, ...) sera décrite dans le champ DataObjectVersion en (3).
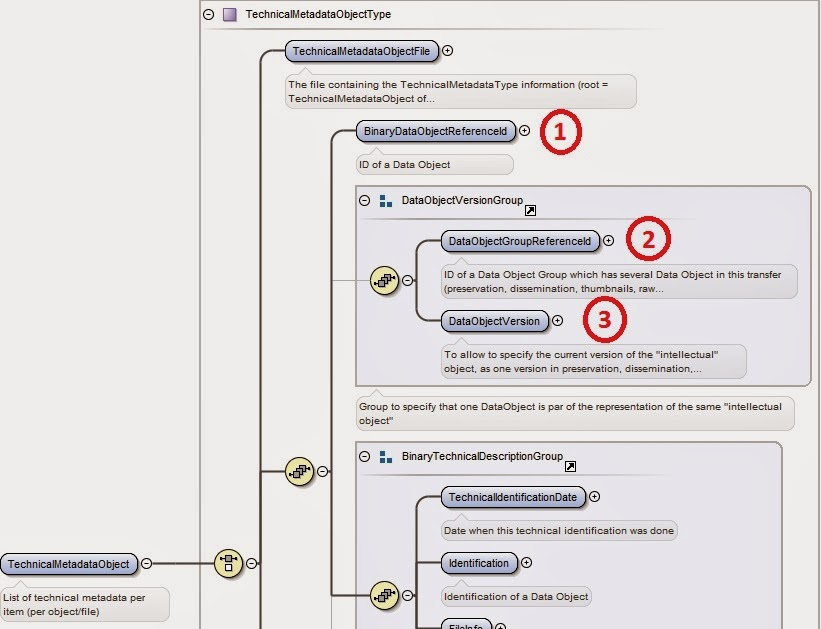 |
| Illustration 10: Groupe et Version d'un DataObject |
Dans
la partie descriptive, illustrée dans le schéma ci-dessous, le
LevelDescriptiveMetadata
contient une référence à un DataObjectReference.
Celui-ci contient un Id
interne et une référence au choix :
- (1) DataObjectId pour un objet ne disposant que d’une seule version et donc sans groupe ;
- (2) DataObjectGroupId pour un groupe d’objet, c’est-à-dire un objet intellectuel.
- L’usage est exclusif : on ne doit pas référencer une version d’un objet d’archives directement dans le schéma descriptif mais uniquement le groupe ainsi constitué auquel il appartient.
 |
| Illustration 11: Usage d'un Groupe ou d'un DataObject unique |
Versement d’un objet d’archive dans un plan de classement pré-existant
Il
s’agit ici de pouvoir par exemple verser un complément d’archives
dans un plan de classement préalablement versé.
Pour
réaliser cette opération, le premier LevelDescriptiveMetadata
contiendra uniquement le LevelManagementMetadataContent
rempli avec le LevelCreationControl
(qui contrôle le requêtage du SAE lors de l’opération d’entrée
d’archives) renseigné pour sélectionner l’entrée correspondant
au plan de classement précédemment versé dans le SAE.
Ainsi
le bloc LevelCreationControl
permet via sa directive Query
de sélectionner par un ensemble de requêtes le nœud dans l’arbre
de classement à partir duquel l’opération d’ajout va se
réaliser. Les requêtes peuvent par exemple porter sur l’identifiant
unique de ce nœud dans le plan de classement (comme une cote).
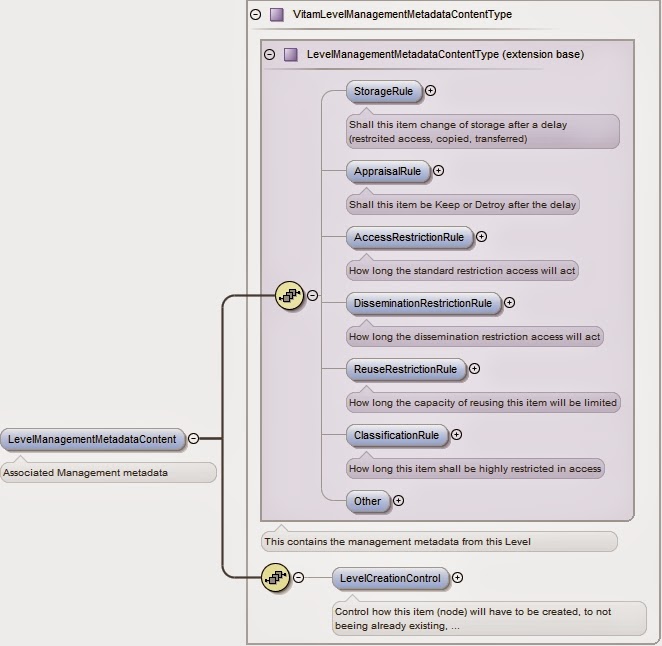 |
| Illustration 12: Element LevelManagementMetadataContent |
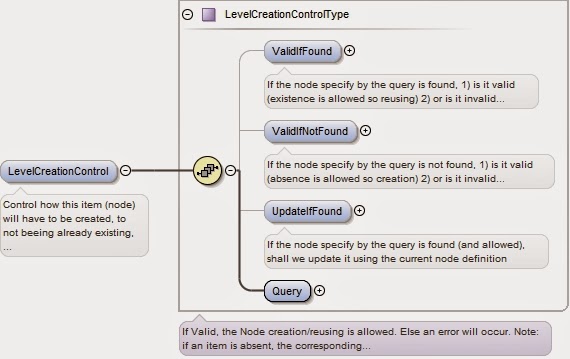 |
| Illustration 13: Element LevelCreationControl |
Ensuite,
tout comme dans le cas précédent (voir Illustration 11: Usage d'un Groupe ou d'un DataObject unique),
on indique l’identifiant du ou des DataObjectId
ou DataObjectGroupId
complémentaires versés dans le bloc DataObjectReference.
Versement d’une version additionnelle à un objet d’archive pré-existant dans le SAE
Il
s’agit ici d’un cas particulier du cas précédent où il s’agit
de verser une version de diffusion complémentaire à un versement
initial réalisé auparavant.
Pour
réaliser cette opération, le premier LevelDescriptiveMetadata
contiendra uniquement le LevelManagementMetadataContent
rempli avec le LevelCreationControl
renseigné pour sélectionner le niveau correspondant de l’objet
numérique intellectuel précédemment versé dans le SAE.
Ensuite,
tout comme dans le cas précédent, on indiquera l’identifiant du
DataObjectId
complémentaire versé dans le bloc DataObjectReference.
Notez que le DataObjectId
ajouté ou celui auquel il est ajouté (en référence du bloc Query)
peut être un BinaryDataObject
ou un PhysicalDataObject.
Merci pour ce post tout à fait explicite qui m'a permis de comprendre ce sujet qui me paraissait bien "barbare" au premier abord ...
RépondreSupprimerMerci pour ces informations.
RépondreSupprimerOn se pose souvent des questions sur le cloud, les coffres fort numérique et l'archivage électronique, pour savoir qui fait quoi.