Présentation préliminaire du schéma VITAM conçu pour le versement d’archives - 1/3
Plan de classement et arborescence
Dans le cadre du programme VITAM, nous devons définir les interfaces externes de la solution logicielle que nous allons développer. Parmi ces interfaces, le schéma de données accompagnant un versement d’archives est un enjeu important.
Dans le cadre des normes et règlements français, nous nous inspirons de la norme MEDONA de l’AFNOR (Z 44-022) qui permet de définir le sur-ensemble des échanges entre partenaires autour d’un Système d’Archivage Électronique (SAE). Nous nous inspirons également de MoReq2010 pour le modèle de données.
En effet MEDONA définit les principes ainsi qu’un exemple de schéma, mais ne spécifie pas les parties liées aux contextes métiers concernés par les archives (plan de classement, métadonnées de gestion, ...). L’objet du schéma VITAM est donc de proposer une extension de la norme MEDONA pour proposer un modèle de données pour le versement d’archives, en tant que première interface d’un SAE.
Plutôt que de faire une seule et unique publication, nous proposons de réaliser des publications par morceaux via mon blog pour obtenir des premiers avis et retour, avant de proposer une version plus « complète » mais toujours ouverte aux commentaires par les canaux plus classiques.
Ce blog étant à caractère personnel, il ne constitue donc pas une publication officielle, mais il m'a semblé intéressant de recueillir des avis avant la mouture finale qui elle suivra une publication officielle, toujours avec appel à commentaires.
Ce blog étant à caractère personnel, il ne constitue donc pas une publication officielle, mais il m'a semblé intéressant de recueillir des avis avant la mouture finale qui elle suivra une publication officielle, toujours avec appel à commentaires.
- Ce premier billet se concentre sur les notions d’arbres et de graphes dans le schéma de métadonnées.
- Le second billet devrait porter sur une classification des métadonnées et leur placement respectif dans un schéma XML plus général.
- Enfin le troisième billet voudra présenter le schéma par thème ainsi que des exemples d’usages.
Vous êtes bien sûr, vous lecteurs, plus que les bienvenus à apporter vos commentaires d'ors et déjà.
I - Un modèle de données inspiré de MoReq2010
Un modèle de données décrit de façon abstraite comment sont représentées les données au sein d'une organisation, d'un métier et/ou d'un système d'information. Le modèle définit la structure des données (structure hiérarchique ou relationnelle par exemple), la manière dont on peut y avoir accès pour les manipuler (mises à jour, suppressions) et pour faire des recherches (comment on y accède ?). Le modèle de données adopté par le programme VITAM est fondé sur la nécessité de prendre en compte un nombre très important de données ayant :
- des structures différentes issues des applications qui les ont produites ;
- et des règles de gestion variables et modifiables dans le temps dépendantes de la réglementation du métier qui les a produites et de la réglementation en matière d'archives publiques.
Ce modèle permet le multi-classement d'un même objet numérique et donc la gestion de plusieurs règles de conservation et d'accès. Le multi-classement offre deux avantages :
- il sera possible de faire coexister le plan de classement du métier qui a produit les données et le plan de classement défini par le service d'archives, ce qui par ailleurs facilitera la gestion de l'archivage intermédiaire et définitif avec la même brique logicielle ;
- le même objet numérique pourra être versé dans la brique par deux producteurs différents sans qu’il soit nécessaire de le stocker deux fois. En revanche, il sera indispensable de conserver les métadonnées associées à l'objet qui seront différentes (héritages multiples) : elles donneront accès à l'objet archivé selon des requêtes distinctes. Cette gestion permettra par ailleurs de gérer des sorts finaux différents en fonction de l'arbre : suppression du chemin permettant d'accéder à un objet pour un type d'utilisateur et conservation du chemin pour d'autres utilisateurs en fonction des droits d'accès liés au droit d'en connaître et aux délais de communicabilité conformément à la réglementation en vigueur. Par ailleurs, ce modèle permettra de gérer l'anonymisation des données le cas échéant (stockage d'une vue anonymisée d'un objet et rattachement à l'AIP d'origine).
II - Les plans de classement
Un plan de classement permet de classer et donc retrouver des archives en fonction d’un contexte déduit de ce classement.
Afin de répondre aux différentes exigences, un plan de classement est conceptuellement un arbre où chaque nœud de l’arbre est un niveau dans le plan de classement, et les feuilles étant les archives elles-mêmes.
Un objet d’archive peut être classé en plusieurs endroits (par exemple une facture est associée à un marché public, un projet ayant passé la commande et la tenue du budget de l’entité concernée), ceci impliquant qu’une feuille puisse dépendre de plusieurs arbres, soit une représentation nommée « graphe dirigé sans cycle » (Directed Acyclic Graph en anglais).
II.1 - Modèle arborescent
Comme l’illustrent les deux schémas ci-dessous, un plan ce classement peut être vu sous la forme d’un arbre. Le premier schéma illustre une vision « métier », le second illustre la vision « XML » technique implémentant cette représentation métier conforme au schéma VITAM que nous proposons.
- Chaque forme est un « nœud » dans un arbre.
- Le sens des flèches indiquent le lien de parenté (le nœud « Fond » est « père » des nœuds « Ss-Fond », eux-mêmes étant les « fils » du nœud « Fond »).
- Les formes nommées « Objet » dans le schéma sont des « feuilles » dans le sens où elles ne possèdent pas de fils et la forme « Fond » est une « racine » au sens où elle n’a pas de père.
- Le nœud « Fond » est un prédécesseur ou un parent de tous les nœuds Objet (il est le père, le grand-père, ou le grand-...-grand père).
Ces dénominations sont issues de la théorie des graphes.
Pour l’exemple, nous nous sommes restreints à une profondeur de 4 (Fond, Sous-fond, Dossier et Objet), mais il est bien sûr non limitatif et notre schéma permet des profondeurs variables et arbitraires, en fonction du contexte métier et archivistique.
 |
| Illustration 1 : Modèle arborescent |
 |
| Illustration 2 : Schéma arborescent |
L’essentiel se situe donc dans la récursivité offerte par le bloc LevelDescriptiveMetadata. Chaque niveau constitue une unité dans le plan de classement comme un Fond, un Sous-fond, un Dossier, … Ces niveaux peuvent donc correspondre au Level of description en ISAD(G), mais peuvent aussi correspondre à un plan de classement plus métier, notamment en archivage intermédiaire voire courant.
II.2 - Multiple classements
Comme l’illustrent les deux schémas suivants, de multiples plans ce classement peuvent aussi être vu sous la forme de multiples arbres, un plan de classement pouvant être relié à un autre. Le premier schéma illustre une vision « métier », le second illustre la vision « XML » technique implémentant cette représentation métier.
Ici un nœud « Dossier » possède plusieurs nœuds parents « Ss-Fond ». Ceci ne constitue plus un arbre (dans un arbre, un nœud n’a au plus qu’un père) mais un graphe dirigé (les flèches) sans cycle (un fils ne peut pas être le père d’un de ses parents). En anglais, ce type de graphe est nommé DAG (Directed Acyclic Graph). Nous indiquons cette notation car elle est couramment utilisée dans la théorie des graphes.
 |
Illustration 3 : Modèle multiple classements |
Chaque nœud dans ces graphes constitue un nœud de métadonnées, informations décrivant le niveau concerné, que nous nommons MAIP par extension des AIP de l’OAIS (M pour Métadonnées).
 |
| Illustration 4 : Schéma Multiple Classements |
On peut voir qu’un « arbre » en rejoint un autre en pointant sur un LevelDescriptiveMetadata existant. Ceci est rendu possible dans le schéma par les blocs suivants :
- LevelDescriptiveMetadataReference dans le bloc de récursivité qui permet de cibler un bloc pré-existant dans le SAE via un objet Query (non décrit ici).
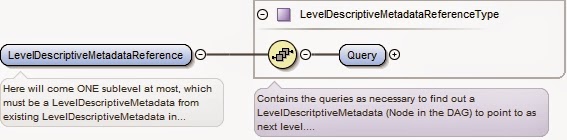 |
| Illustration 5 : LevelDescriptiveMetadataReference |
- RefId dans le bloc LevelDescriptiveMetadata qui permet de cibler un bloc déjà décrit dans le même transfert.
 |
| Illustration 6: LevelDescriptiveMetadata – RefId |
Notez que la récursivité du plan de classement est assurée via cet objet LevelDescriptiveMetadata qui se répète dans sa définition (1 à n LevelDescriptiveMetadata sous éléments).
II.3 - Gestion des héritages
En raison du modèle arborescent, des propriétés de gestion placées dans un nœud s’appliquent par défaut à tous ses fils. Ainsi si une propriété indique que la durée de conservation est de 10 ans, l’ensemble de ses fils ont eux aussi cette propriété de conservation de 10 ans.
Il reste cependant à gérer les cas de conflits qui peuvent apparaître :
- Un père possède une propriété d’une valeur X et un de ses fils possède cette même propriété avec une valeur Y :
- Si la propriété est inclusive : les propriétés du père et du fils sont additionnées à partir du fils et pour tous les descendants (la valeur de la propriété sera X et Y) ;
- Si la propriété est exclusive : les propriétés du père sont ignorées lorsque le fils les définit également (mode « annule et remplace », soit la valeur Y).
- En mode graphe, un fils dépendant de deux pères, chacun d’entre eux possédant la même propriété avec deux valeurs différentes :
- Si la propriété est inclusive : les propriétés des deux pères sont additionnées à partir du fils et pour tous les descendants ;
- Si la propriété est exclusive : les propriétés des deux pères doivent faire l’objet d’une sélection, selon des règles métiers, notamment de priorité de valeurs.
 |
| Illustration 7: Modèle d'héritage |
A noter que l’ensemble des métadonnées de description sont inclusives. Seules les métadonnées de gestion (droits d’accès, durée de conservation, …) peuvent être exclusives.
Dans le prochain épisode, je vous présenterais selon le même format notre classification des métadonnées et leur placement respectif dans notre schéma XML.
D'ici là, n'hésitez pas à me faire part de vos commentaires !!
Merci pour ce post très intéressant et informatif qui ne pourra que m'aider dans mes activités professionnelles. Bonne continuation !
RépondreSupprimerThis is a very interesting approach to data modeling for archival purposes.
RépondreSupprimer